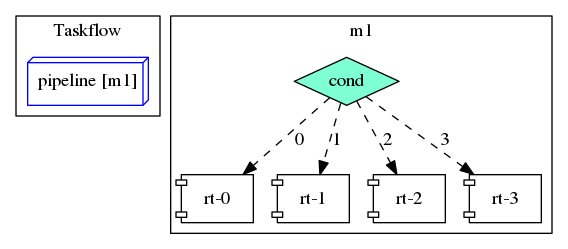
Taskflow provides a task-parallel pipeline programming framework for you to create a pipeline scheduling framework. Pipeline parallelism refers to a parallel execution of multiple data tokens through a linear chain of pipes or stages. Each stage processes the data token sent from the previous stage, applies the given callable to that data token, and then sends the result to the next stage. Multiple data tokens can be processed simultaneously across different stages.
Include the Header
You need to include the header file, taskflow/algorithm/pipeline.hpp, for creating a pipeline scheduling framework.
Understand the Pipeline Scheduling Framework
A tf::Pipeline object is a composable graph to create a pipeline scheduling framework through a module task in a taskflow (see Composable Tasking). Unlike the conventional pipeline programming frameworks (e.g., Intel TBB Parallel Pipeline), Taskflow's pipeline algorithm does not provide any data abstraction, which often restricts users from optimizing data layouts in their applications, but a flexible framework for users to customize their application data atop an efficient pipeline scheduling framework.
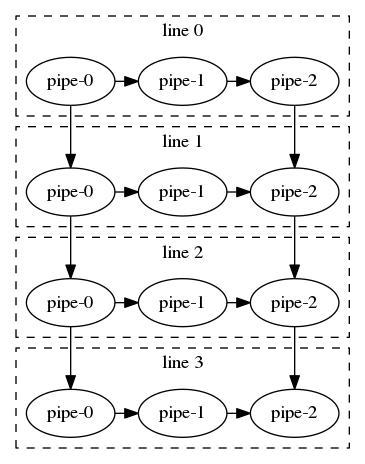
The figure above gives an example of our pipeline scheduling framework. The framework consists of three pipes (serial-parallel-serial stages) and four lines (maximum parallelism), where each line processes at most one data token. A pipeline of three pipes and four lines will propagate each data token through a sequential chain of three pipes and can simultaneously process up to four data tokens at the four lines. Each edge represents a task dependency. For example, the edge from pipe-0 to pipe-1 in line 0 represents the task dependency between the first and the second pipes in the first line; the edge from pipe-0 in line 0 to pipe-0 in line 1 represents the task dependency between two adjacent lines when processing two data tokens at the same pipe. Each pipe can be either a serial type or a parallel type, where a serial pipe processes data tokens sequentially and a parallel pipe processes different data tokens simultaneously.
- Note
- Due to the nature of pipeline, Taskflow requires the first pipe to be a serial type. The pipeline scheduling algorithm operates in a circular fashion with a factor of line count.
Create a Pipeline Module Task
Taskflow leverages modern C++ and template techniques to strike a balance between the expressiveness and generality in designing the pipeline programming model. In general, there are three steps to create a pipeline application:
- Define the pipeline structure (e.g., pipe type, pipe callable, stopping rule, line count)
- Define the data storage and layout, if needed for the application
- Define the pipeline taskflow graph using composition
The following code creates a pipeline scheduling framework using the example from the previous section. The framework schedules a total of five scheduling tokens labeled from 0 to 4. The first pipe stores the token identifier in a custom data storage, buffer, and each of the rest pipes adds one to the input data from the result of the previous pipe and stores the result into the corresponding line entry in the buffer.
3:
4:
5: const size_t num_lines = 4;
6:
7:
9:
10:
11:
14:
15: if(pf.token() == 5) {
16: pf.stop();
17: }
18:
19: else {
20: printf("pipe 0: input token = %zu\n", pf.token());
21: buffer[pf.line()] = pf.token();
22: }
23: }},
24:
27: "pipe 1: input buffer[%zu] = %d\n",
28: pf.line(), buffer[pf.line()]
29: );
30:
31: buffer[pf.line()] = buffer[pf.line()] + 1;
32: }},
33:
36: "pipe 2: input buffer[%zu] = %d\n",
37: pf.line(), buffer[pf.line()]
38: );
39:
40: buffer[pf.line()] = buffer[pf.line()] + 1;
41: }}
42: );
43:
44:
46:
47:
48: executor.
run(taskflow).wait();
class to create an executor for running a taskflow graph
Definition executor.hpp:50
tf::Future< void > run(Taskflow &taskflow)
runs a taskflow once
Definition executor.hpp:1573
Task composed_of(T &object)
creates a module task for the target object
Definition flow_builder.hpp:812
class to create a pipe object for a pipeline stage
Definition pipeline.hpp:136
class to create a pipeflow object used by the pipe callable
Definition pipeline.hpp:42
class to create a pipeline scheduling framework
Definition pipeline.hpp:312
class to create a task handle over a node in a taskflow graph
Definition task.hpp:187
const std::string & name() const
queries the name of the task
Definition task.hpp:499
class to create a taskflow object
Definition core/taskflow.hpp:73
taskflow namespace
Definition small_vector.hpp:27
PipeType
enumeration of all pipe types
Definition pipeline.hpp:105
Debrief:
- Lines 4-5 define the structure of the pipeline scheduling framework
- Line 8 defines the data storage as an one-dimensional array of
num_lines integers
- Line 12 defines the number of lines in the pipeline
- Lines 13-23 define the first serial pipe, which will stop the pipeline scheduling at the fifth token
- Lines 25-32 define the second parallel pipe
- Lines 34-41 define the third serial pipe
- Line 45 defines the pipeline taskflow graph using composition
- Line 48 executes the taskflow
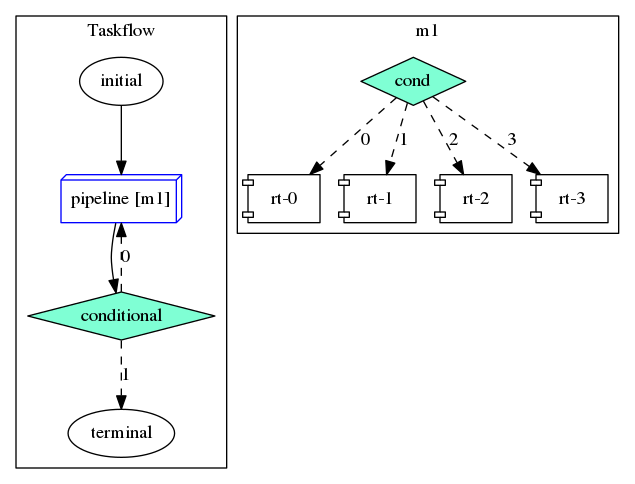
Taskflow leverages Runtime Tasking and Composable Tasking to implement the pipeline scheduling framework. The taskflow graph of this pipeline example is shown as follows, where 1) one condition task is used to decide which runtime task to run and 2) four runtime tasks is used to schedule tokens at four parallel lines, respectively.
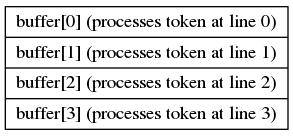
In this example, we customize the data storage, buffer, as an one-dimensional array of 4 integers, since the pipeline structure defines only four parallel lines. Each entry of buffer stores stores the data being processed in the corresponding line. For example, buffer[1] stores the processed data at line 1. The following figure shows the data layout of buffer.
- Note
- In practice, you may need to add padding to the data type of the buffer or align it with the cacheline size to avoid false sharing. If the data type varies at different pipes, you can use std::variant to store the data types in a uniform storage.
For each scheduling token, you can use tf::Pipeflow::line() to get its line identifier and tf::Pipeflow::pipe() to get its pipe identifier. For example, if a scheduling token is at the third pipe of the forth line, tf::Pipeflow::line() will return 3 and tf::Pipeflow::pipe() will return 2 (index starts from 0). To stop the execution of the pipeline, you need to call tf::Pipeflow::stop() at the first pipe. Once the stop signal has been triggered, the pipeline will stop scheduling any new tokens after the callable. As we can see from this example, tf::Pipeline gives you the full control to customize your application data on top of a pipeline scheduling framework.
- Note
- Calling tf::Pipeflow::stop() not at the first pipe has no effect on the pipeline scheduling.
- In most cases, std::thread::hardware_concurrency is a good number for line count.
Our pipeline algorithm schedules tokens in a circular manner, with a factor of num_lines. That is, token t will be processed at line t % num_lines. The following snippet shows one of the possible outputs of this pipeline program:
pipe 0: input token = 0
pipe 1: input buffer[0] = 0
pipe 2: input buffer[0] = 1
pipe 0: input token = 1
pipe 1: input buffer[1] = 1
pipe 2: input buffer[1] = 2
pipe 0: input token = 2
pipe 1: input buffer[2] = 2
pipe 2: input buffer[2] = 3
pipe 0: input token = 3
pipe 1: input buffer[3] = 3
pipe 2: input buffer[3] = 4
pipe 0: input token = 4
pipe 1: input buffer[0] = 4
pipe 2: input buffer[0] = 5
There are a total of five tokens running through three pipes. Each pipes prints its input data value, except the first pipe that prints its token identifier. Since the second pipe is a parallel pipe, the output can interleave.
Connect Pipeline with Other Tasks
You can connect the pipeline module task with other tasks to create a taskflow application that embeds one or multiple pipeline algorithms. We describe three common examples below:
Example 1: Iterate a Pipeline
This example emulates a data streaming application that iteratively runs a stream of data through a pipeline using conditional tasking. The taskflow graph consists of one pipeline module task and one condition task. The pipeline module task processes a stream of data. The condition task decides the availability of data and reruns the pipeline when the next stream of data becomes available.
3:
4: const size_t num_lines = 4;
5:
6: int i = 0, N = 0;
7:
9:
10:
11:
14:
15: if(i++ == 5) {
16: pf.stop();
17: }
18:
19: else {
20: printf("stage 0: input token = %zu\n", pf.token());
21: buffer[pf.line()] = pf.token();
22: }
23: }},
24:
27: "stage 1: input buffer[%zu] = %d\n",
28: pf.line(), buffer[pf.line()]
29: );
30:
31: buffer[pf.line()] = buffer[pf.line()] + 1;
32: }},
33:
36: "stage 2: input buffer[%zu] = %d\n",
37: pf.line(), buffer[pf.line()]
38: );
39:
40: buffer[pf.line()] = buffer[pf.line()] + 1;
41: }}
42: );
43:
45: i = 0;
46: if (++N < 2) {
48: return 0;
49: }
50: else {
51: return 1;
52: }
53: }).name("conditional");
54:
55:
59: .name("initial");
61: .name("stop");
62:
63:
66: conditional.
precede(pipeline, stop);
67:
68:
69: executor.
run(taskflow).wait();
Task emplace(C &&callable)
creates a static task
Definition flow_builder.hpp:742
Task & precede(Ts &&... tasks)
adds precedence links from this to other tasks
Definition task.hpp:420
Debrief:
- Lines 4-5 define the structure of the pipeline scheduling framework
- Line 8 defines the data storage as an one-dimensional array (
num_lines integers)
- Line 12 defines the number of lines in the pipeline
- Lines 13-23 define the first serial pipe, which will stop the pipeline scheduling when
i is 5
- Lines 25-32 define the second parallel pipe
- Lines 34-41 define the third serial pipe
- Lines 44-53 define a condition task which returns 0 when
N is less than 2, otherwise returns 1
- Line 45 resets variable
i
- Lines 56-57 define the pipeline graph using composition
- Lines 58-61 define two static tasks
- Line 64-66 define the task dependency
- Line 69 executes the taskflow
The taskflow graph of this pipeline example is illustrated as follows:
The following snippet shows one of the possible outputs:
initial
stage 0: input token = 0
stage 1: input buffer[0] = 0
stage 2: input buffer[0] = 1
stage 0: input token = 1
stage 1: input buffer[1] = 1
stage 2: input buffer[1] = 2
stage 0: input token = 2
stage 1: input buffer[2] = 2
stage 2: input buffer[2] = 3
stage 0: input token = 3
stage 1: input buffer[3] = 3
stage 2: input buffer[3] = 4
stage 0: input token = 4
stage 1: input buffer[0] = 4
stage 2: input buffer[0] = 5
Rerun the pipeline
stage 0: input token = 5
stage 1: input buffer[1] = 5
stage 2: input buffer[1] = 6
stage 0: input token = 6
stage 1: input buffer[2] = 6
stage 2: input buffer[2] = 7
stage 0: input token = 7
stage 1: input buffer[3] = 7
stage 2: input buffer[3] = 8
stage 0: input token = 8
stage 1: input buffer[0] = 8
stage 2: input buffer[0] = 9
stage 0: input token = 9
stage 1: input buffer[1] = 9
stage 2: input buffer[1] = 10
stop
The pipeline runs twice as controlled by the condition task conditional. The starting token in the second run of the pipeline is 5 rather than 0 because the pipeline keeps a stateful number of tokens. The last token is 9, which means the pipeline processes in total 10 scheduling tokens. The first five tokens (token 0 to 4) are processed in the first run, and the remaining five tokens (token 5 to 9) are processed in the second run. In the condition task, we use N as a decision-making counter to process the next stream of data.
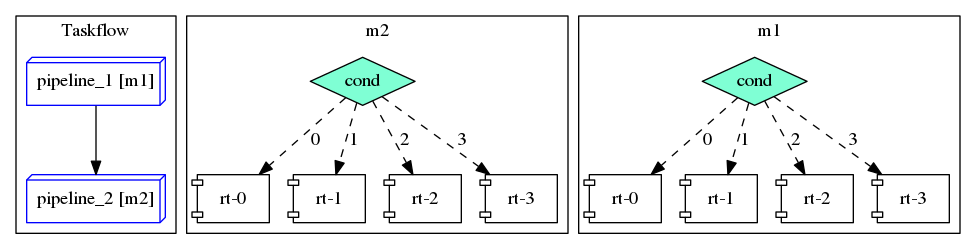
Example 2: Concatenate Two Pipelines
This example demonstrates two concatenated pipelines where a sequence of data tokens run synchronously from one pipeline to another pipeline. The first pipeline task precedes the second pipeline task.
3:
4:
5: const size_t num_lines = 4;
6:
7:
10:
11:
12:
15:
16: if(pf.token() == 4) {
17: pf.stop();
18: }
19:
20: else {
21: printf("pipeline 1, pipe 0: input token = %zu\n", pf.token());
22: buffer_1[pf.line()] = pf.token();
23: }
24: }},
25:
28: "pipeline 1, pipe 1: input buffer_1[%zu] = %d\n",
29: pf.line(), buffer_1[pf.line()]
30: );
31:
32: buffer_1[pf.line()] = buffer_1[pf.line()] + 1;
33: }},
34:
37: "pipeline 1, pipe 2: input buffer_1[%zu] = %d\n",
38: pf.line(), buffer_1[pf.line()]
39: );
40:
41: buffer_1[pf.line()] = buffer_1[pf.line()] + 1;
42: }}
43: );
44:
45:
46:
49: [&buffer_2, &buffer_1](
tf::Pipeflow& pf) mutable{
50:
51: if(pf.token() == 4) {
52: pf.stop();
53: }
54:
55: else {
56:
printf(
"pipeline 2, pipe 0: input value = %d\n", buffer_1[pf.line()]);
57: buffer_2[pf.line()] = buffer_1[pf.line()];
58: }
59: }},
60:
63: "pipeline 2, pipe 1: input buffer_2[%zu] = %d\n",
64: pf.line(), buffer_2[pf.line()]
65: );
66:
67: buffer_2[pf.line()] = buffer_2[pf.line()] + 1;
68: }},
69:
72: "pipeline 2, pipe 2: input buffer_2[%zu] = %d\n",
73: pf.line(), buffer_2[pf.line()]
74: );
75:
76: buffer_2[pf.line()] = buffer_2[pf.line()] + 1;
77: }}
78: );
79:
80:
83:
84:
85: pipeline_1.
precede(pipeline_2);
86:
87:
88: executor.
run(taskflow).wait();
Debrief:
- Line 8 defines the data storage (
num_lines integers) for pipeline pl_1
- Line 9 defines the data storage (
num_lines integers) for pipeline pl_2
- Lines 14-24 define the first serial pipe in
pl_1
- Lines 26-33 define the second parallel pipe in
pl_1
- Lines 35-42 define the third serial pipe in
pl_1
- Lines 48-59 define the first serial pipe in
pl_2 that takes the results of pl_1 as inputs
- Lines 61-68 define the second parallel pipe in
pl_2
- Lines 70-77 define the third serial pipe in
pl_2
- Lines 81-82 define the pipeline graphs using composition
- Line 85 defines the task dependency
- Line 88 runs the taskflow
The taskflow graph of this pipeline example is illustrated as follows:
The following snippet shows one of the possible outputs:
pipeline 1, pipe 0: input token = 0
pipeline 1, pipe 1: input buffer_1[0] = 0
pipeline 1, pipe 2: input buffer_1[0] = 1
pipeline 1, pipe 0: input token = 1
pipeline 1, pipe 1: input buffer_1[1] = 1
pipeline 1, pipe 2: input buffer_1[1] = 2
pipeline 1, pipe 0: input token = 2
pipeline 1, pipe 1: input buffer_1[2] = 2
pipeline 1, pipe 2: input buffer_1[2] = 3
pipeline 1, pipe 0: input token = 3
pipeline 1, pipe 1: input buffer_1[3] = 3
pipeline 1, pipe 2: input buffer_1[3] = 4
pipeline 2, pipe 1: input value = 2
pipeline 2, pipe 2: input buffer_2[0] = 2
pipeline 2, pipe 3: input buffer_2[0] = 3
pipeline 2, pipe 1: input value = 3
pipeline 2, pipe 2: input buffer_2[1] = 3
pipeline 2, pipe 3: input buffer_2[1] = 4
pipeline 2, pipe 1: input value = 4
pipeline 2, pipe 2: input buffer_2[2] = 4
pipeline 2, pipe 3: input buffer_2[2] = 5
pipeline 2, pipe 1: input value = 5
pipeline 2, pipe 2: input buffer_2[3] = 5
pipeline 2, pipe 3: input buffer_2[3] = 6
The output of pipelines pl_1 and pl_2 can be different from run to run because their second pipes are both parallel types. Due to the task dependency between pipeline_1 and pipeline_2, the output of pl_1 precedes the output of pl_2.
Example 3: Define Multiple Parallel Pipelines
This example creates two independent pipelines that run in parallel on different data sets.
3:
4:
5: const size_t num_lines = 4;
6:
7:
10:
11:
12:
15:
16: if(pf.token() == 5) {
17: pf.stop();
18: }
19:
20: else {
21: printf("pipeline 1, pipe 0: input token = %zu\n", pf.token());
22: buffer_1[pf.line()] = pf.token();
23: }
24: }},
25:
28: "pipeline 1, pipe 1: input buffer_1[%zu] = %d\n",
29: pf.line(), buffer_1[pf.line()]
30: );
31:
32: buffer_1[pf.line()] = buffer_1[pf.line()] + 1;
33: }},
34:
37: "pipeline 1, pipe 2: input buffer_1[%zu] = %d\n",
38: pf.line(), buffer_1[pf.line()]
39: );
40:
41: buffer_1[pf.line()] = buffer_1[pf.line()] + 1;
42: }}
43: );
44:
45:
46:
49:
50: if(pf.token() == 5) {
51: pf.stop();
52: }
53:
54: else {
55:
printf(
"pipeline 2, pipe 0: input token = %zu\n", pf.token());
56: buffer_2[pf.line()] = "pipeline";
57: }
58: }},
59:
62: "pipeline 2, pipe 1: input buffer_2[%zu] = %d\n",
63: pf.line(), buffer_2[pf.line()]
64: );
65:
66: buffer_2[pf.line()] = buffer_2[pf.line()];
67: }},
68:
71: "pipeline 2, pipe 2: input buffer_2[%zu] = %d\n",
72: pf.line(), buffer_2[pf.line()]
73: );
74:
75: buffer_2[pf.line()] = buffer_2[pf.line()];
76: }}
77: );
78:
84: .name("initial");
85:
86: initial.
precede(pipeline_1, pipeline_2);
87:
88: executor.
run(taskflow).wait();
Debrief:
- Line 8 defines the data storage (
num_lines integers) for pipeline pl_1
- Line 9 defines the data storage (
num_lines integers) for pipeline pl_2
- Lines 14-24 define the first serial pipe in
pl_1
- Lines 26-33 define the second parallel pipe in
pl_1
- Lines 35-42 define the third serial pipe in
pl_1
- Lines 48-58 define the first serial pipe in
pl_2
- Lines 60-67 define the second parallel pipe in
pl_2
- Lines 69-76 define the third serial pipe in
pl_2
- Lines 79-82 define the pipeline graphs using composition
- Lines 83-84 define a static task.
- Line 86 defines the task dependency
- Line 88 runs the taskflow
The taskflow graph of this pipeline example is illustrated as follows:
The following snippet shows one of the possible outputs:
initial
pipeline 2, pipe 0: input token = 0
pipeline 2, pipe 1: input buffer_2[0] = 0
pipeline 2, pipe 2: input buffer_2[0] = 1
pipeline 1, pipe 0: input token = 0
pipeline 1, pipe 1: input buffer_1[0] = 0
pipeline 1, pipe 2: input buffer_1[0] = 1
pipeline 1, pipe 0: input token = 1
pipeline 1, pipe 1: input buffer_1[1] = 1
pipeline 1, pipe 0: input token = 2
pipeline 1, pipe 1: input buffer_1[2] = 2
pipeline 1, pipe 0: input token = 3
pipeline 1, pipe 1: input buffer_1[3] = 3
pipeline 1, pipe 0: input token = 4
pipeline 1, pipe 1: input buffer_1[0] = 4
pipeline 2, pipe 0: input token = 1
pipeline 2, pipe 1: input buffer_2[1] = 1
pipeline 2, pipe 0: input buffer_2[1] = 2
pipeline 2, pipe 0: input token = 2
pipeline 2, pipe 1: input buffer_2[2] = 2
pipeline 2, pipe 2: input buffer_2[2] = 3
pipeline 2, pipe 0: input token = 3
pipeline 2, pipe 1: input buffer_2[3] = 3
pipeline 2, pipe 2: input buffer_2[3] = 4
pipeline 2, pipe 0: input token = 4
pipeline 2, pipe 1: input buffer_2[0] = 4
pipeline 2, pipe 2: input buffer_2[0] = 5
pipeline 1, pipe 2: input buffer_1[1] = 2
pipeline 1, pipe 2: input buffer_1[2] = 3
pipeline 1, pipe 2: input buffer_1[3] = 4
pipeline 1, pipe 2: input buffer_1[0] = 5
Because pipeline pl_1 and pipeline pl_2 are running in parallel, their outputs may interleave.
Reset a Pipeline
Our pipeline scheduling framework keeps a stateful number of scheduled tokens at each submitted run. You can reset the pipeline to the initial state using tf::Pipeline::reset(), where the number of scheduled tokens will start from zero in the next run. Borrowed from Example 1: Iterate a Pipeline, the program below resets the pipeline at the second iteration (inside the condition task) so the scheduling token will start from zero in the next run.
const size_t num_lines = 4;
if(pf.token() == 5) {
pf.stop();
}
else {
printf("pipe 0: input token = %zu\n", pf.token());
buffer[pf.line()] = pf.token();
}
}},
"pipe 1: input buffer_1[%zu] = %d\n", pf.line(), buffer[pf.line()]
);
buffer[pf.line()] = buffer[pf.line()] + 1;
}},
"pipe 2: input buffer[%zu][%zu] = %d\n", pf.line(), buffer[pf.line()]
);
buffer[pf.line()] = buffer[pf.line()] + 1;
}}
);
if (++N < 2) {
return 0;
}
else {
return 1;
}
}).name("conditional");
.name("initial");
.name("stop");
conditional.
precede(pipeline, stop);
executor.
run(taskflow).wait();
void reset()
resets the pipeline
Definition pipeline.hpp:497
The following snippet shows one of the possible outputs:
initial
pipe 0: input token = 0
pipe 1: input buffer_1[0] = 0
pipe 2: input buffer_1[0] = 1
pipe 0: input token = 1
pipe 1: input buffer_1[1] = 1
pipe 2: input buffer_1[1] = 2
pipe 0: input token = 2
pipe 1: input buffer_1[2] = 2
pipe 2: input buffer_1[2] = 3
pipe 0: input token = 3
pipe 1: input buffer_1[3] = 3
pipe 2: input buffer_1[3] = 4
pipe 0: input token = 4
pipe 1: input buffer_1[0] = 4
pipe 2: input buffer_1[0] = 5
Rerun the pipeline
pipe 0: input token = 0
pipe 1: input buffer_1[0] = 0
pipe 2: input buffer_1[0] = 1
pipe 0: input token = 1
pipe 1: input buffer_1[1] = 1
pipe 2: input buffer_1[1] = 2
pipe 0: input token = 2
pipe 1: input buffer_1[2] = 2
pipe 2: input buffer_1[2] = 3
pipe 0: input token = 3
pipe 1: input buffer_1[3] = 3
pipe 2: input buffer_1[3] = 4
pipe 0: input token = 4
pipe 1: input buffer_1[0] = 4
pipe 2: input buffer_1[0] = 5
stop
The output can be different from run to run, since the second pipe is a parallel type. At the second iteration from the condition task, we reset the pipeline so the token identifier starts from 0 rather than 5.
Learn More about Taskflow Pipeline
Visit the following pages to learn more about pipeline:
- Parallel Scalable Pipeline
- Text Processing Pipeline
- Graph Processing Pipeline
- Taskflow Processing Pipeline