|
Taskflow
3.2.0-Master-Branch
|
|
Taskflow
3.2.0-Master-Branch
|
We study a graph processing pipeline that propagates a sequence of linearly dependent tasks over a dependency graph. In this particular workload, we will learn how to transform task graph parallelism into pipeline parallelism.
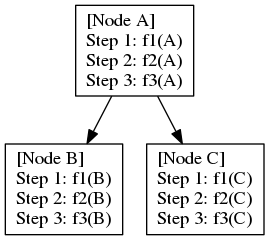
Given a directed acyclic graph (DAG), where each node encapsulates a sequence of linearly dependent tasks, namely stage tasks, and each edge represents a dependency between two tasks at the same stages of adjacent nodes. For example, assuming fi(u) represents the ith-stage task of node u, a dependency from u to v requires fi(u) to run before fi(v). The following figures shows an example of three stage tasks in a DAG of three nodes (A, B, and C) and two dependencies (A->B and A->C):
While we can directly create a taskflow for the DAG (i.e., each task in the taskflow runs f1, f2, and f3 sequentially), we can describe the parallelism as a three-stage pipeline that propagates a topological order of the DAG through three stage tasks. Consider a valid topological order of this DAG, A, B, C, its pipeline parallelism can be illustrated in the following figure:
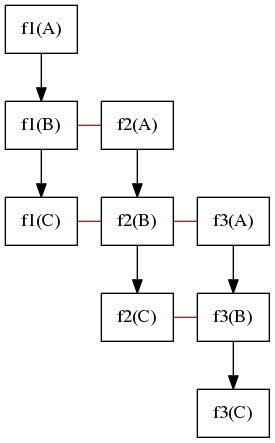
At the beginning, f1(A) runs first. When f1(A) completes, it moves on to f2(A) and, meanwhile, f1(B) can start to run together with f2(A), and so on so forth. The straight line represents two parallel tasks that can overlap in time in the pipeline. For example, f3(A), f2(B), and f1(C) can run simultaneously. The following figures shows the task dependency graph of this pipeline workload:
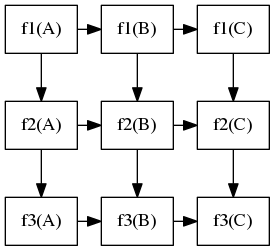
As we can see, tasks in diagonal lines (lower-left to upper-right) can run in parallel. This type of parallelism is also referred to as wavefront parallelism, which sweeps parallel elements in a diagonal direction.
Using the example from the previous section, we create a three-stage pipeline that encapsulates the three stage tasks (f1, f2, f3) in three pipes. By finding a topological order of the graph, we can transform the node dependency into a sequence of linearly dependent data tokens to feed into the pipeline. The overall implementation is shown below:
The first step is to find a valid topological order of the graph, such that we can transform the graph dependency into a linear sequence. In this example, we simply hard-code it:
This particular workload does not propagate data directly through the pipeline. In most situations, data is directly stored in a custom graph data structure, and the stage function will just need to know which node to process. For demo's sake, we simply output a message to show which stage function is processing which node:
The pipe structure is straightforward. Each pipe encapsulates the corresponding stage function and passes the node into the function argument. The first pipe will cease the pipeline scheduling when it has processed all nodes. To identify which node is being processed at a running pipe, we use tf::Pipeflow::token to find the index:
To build up the taskflow for the pipeline, we create a module task with the defined pipeline structure and connect it with two tasks that output helper messages before and after the pipeline:
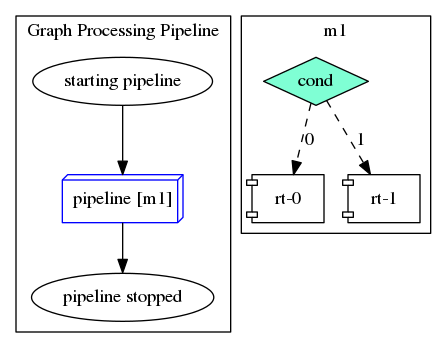
Finally, we submit the taskflow to the execution and run it once:
Three possible outputs are shown below: