|
Taskflow
3.2.0-Master-Branch
|
|
Taskflow
3.2.0-Master-Branch
|
Following up on Matrix Multiplication, this page studies how to accelerate a matrix multiplication workload on a GPU using tf::cudaFlow.
GPU can perform a lot of parallel computations more than CPUs. It is especially useful for data-intensive computing such as matrix multiplication. With GPU, we express the parallel patterns at a fine-grained level. The kernel, written in CUDA, is described as follows:
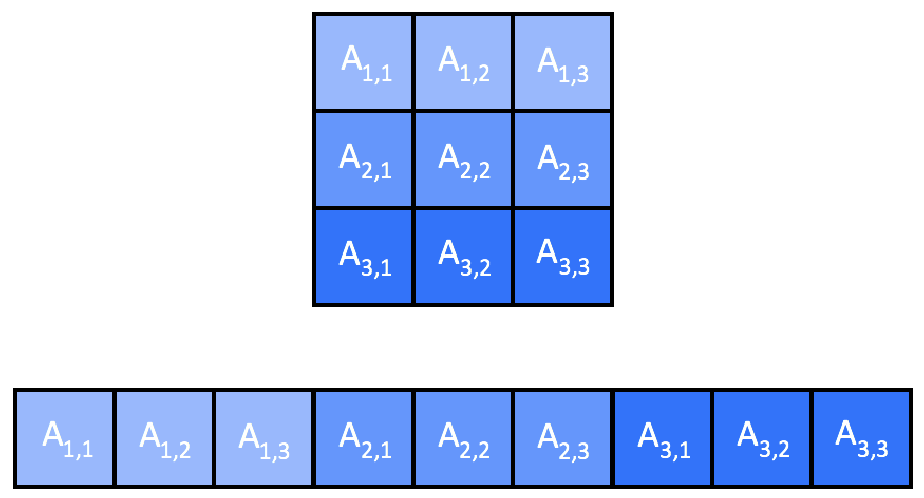
Each CUDA thread corresponds to an element of C and compute its result. Instead of storing each matrix in a 2D array, we use 1D layout to ease the data transfer between CPU and GPU. In a row-major layout, an element (x, y) in the 2D matrix can be addressed at x * width + y in the transformed 1D layout.
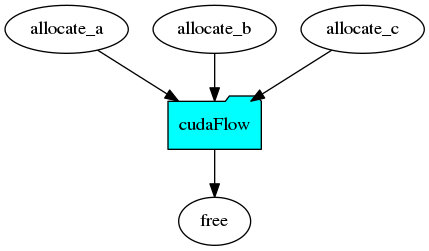
The next step is to allocate memory for A, B, and C at a GPU. We create three tasks each calling cudaMalloc to allocate space for one matrix. Then, we create a cudaFlow to offload matrix multiplication to a GPU. The entire code is described as follows:
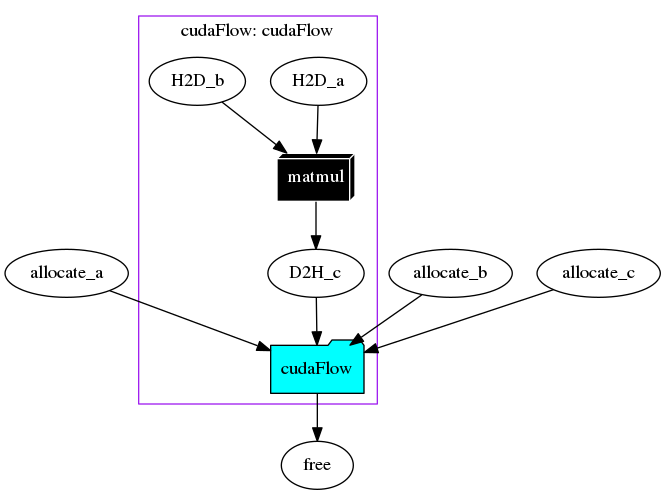
Within the cudaFlow, we create two host-to-device (H2D) tasks that copy data from A and B to da and db, one device-to-host (D2H) task that copies the result from dc to C, and one kernel task that launches matmul on the GPU (by default, GPU 0). H2D tasks precede the kernel and the kernel precedes the D2H task. These GPU operations form a GPU task graph managed by a cudaFlow. The first dump of the taskflow gives the following graph:
A cudaFlow encapsulates a GPU task dependency graph similar to a tf::Subflow (see Dynamic Tasking). In order to visualize it, we need to execute the graph first and then dump the taskflow.
We run three versions of matrix multiplication, sequential CPU, parallel CPUs, and one GPU, on a machine of 12 Intel i7-8700 CPUs at 3.20 GHz and a Nvidia RTX 2080 GPU using various matrix sizes of A, B, and C.
| A | B | C | CPU Sequential | CPU Parallel | GPU Parallel |
|---|---|---|---|---|---|
| 10x10 | 10x10 | 10x10 | 0.142 ms | 0.414 ms | 82 ms |
| 100x100 | 100x100 | 100x100 | 1.641 ms | 0.733 ms | 83 ms |
| 1000x1000 | 1000x1000 | 1000x1000 | 1532 ms | 504 ms | 85 ms |
| 2000x2000 | 2000x2000 | 2000x2000 | 25688 ms | 4387 ms | 133 ms |
| 3000x3000 | 3000x3000 | 3000x3000 | 104838 ms | 16170 ms | 214 ms |
| 4000x4000 | 4000x4000 | 4000x4000 | 250133 ms | 39646 ms | 427 ms |
As the matrix size increases, the speed-up of GPU over CPUs becomes prominent. For example, at 4000x4000, the GPU runtime is 585.8 times faster than the sequential CPU runtime and is 92.8 times faster than the parallel CPU solutions.