Following up on k-means Clustering, this page studies how to accelerate a k-means workload on a GPU using tf::cudaFlow.
Define the k-means Kernels
Recall that the k-means algorithm has the following steps:
-
Step 1: initialize k random centroids
-
Step 2: for every data point, find the nearest centroid (L2 distance or other measurements) and assign the point to it
-
Step 3: for every centroid, move the centroid to the average of the points assigned to that centroid
-
Step 4: go to Step 2 until converged (no more changes in the last few iterations) or maximum iterations reached
We observe Step 2 and Step 3 of the algorithm are parallelizable across individual points for use to harness the power of GPU:
-
for every data point, find the nearest centroid (L2 distance or other measurements) and assign the point to it
-
for every centroid, move the centroid to the average of the points assigned to that centroid.
At a fine-grained level, we request one GPU thread to work on one point for Step 2 and one GPU thread to work on one centroid for Step 3.
__global__ void assign_clusters(
float* px, float* py, int N,
float* mx, float* my, float* sx, float* sy, int K, int* c
) {
const int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index >= N) {
return;
}
float x = px[index];
float y = py[index];
float best_dance = FLT_MAX;
int best_k = 0;
for (int k = 0; k < K; ++k) {
float d = L2(x, y, mx[k], my[k]);
if (d < best_d) {
best_d = d;
best_k = k;
}
}
atomicAdd(&sx[best_k], x);
atomicAdd(&sy[best_k], y);
atomicAdd(&c [best_k], 1);
}
__global__ void compute_new_means(
float* mx, float* my, float* sx, float* sy, int* c
) {
int k = threadIdx.x;
}
When we recompute the cluster centroids to be the mean of all points assigned to a particular centroid, multiple GPU threads may access the sum arrays, sx and sy, and the count array, c. To avoid data race, we use a simple atomicAdd method.
Define the k-means cudaFlow
Based on the two kernels, we can define the cudaFlow for the k-means workload below:
void kmeans_gpu(
) {
float *d_px, *d_py, *d_mx, *d_my, *d_sx, *d_sy, *d_c;
for(int i=0; i<K; ++i) {
h_mx.push_back(h_px[i]);
h_my.push_back(h_py[i]);
}
tf::Task allocate_px = taskflow.emplace([&](){
cudaMalloc(&d_px, N*sizeof(float));
}).name("allocate_px");
tf::Task allocate_py = taskflow.emplace([&](){
cudaMalloc(&d_py, N*sizeof(float));
}).name("allocate_py");
tf::Task allocate_mx = taskflow.emplace([&](){
cudaMalloc(&d_mx, K*sizeof(float)); }
).name("allocate_mx");
tf::Task allocate_my = taskflow.emplace([&](){
cudaMalloc(&d_my, K*sizeof(float));
}).name("allocate_my");
tf::Task allocate_sy = taskflow.emplace([&](){
cudaMalloc(&d_sy, K*sizeof(float));
}).name("allocate_sy");
tf::Task allocate_c = taskflow.emplace([&](){
cudaMalloc(&d_c, K*sizeof(float));
}).name("allocate_c");
cf.
copy(d_px, h_px.data(), N).
name(
"h2d_px");
cf.
copy(d_py, h_py.data(), N).
name(
"h2d_py");
cf.
copy(d_mx, h_mx.data(), K).
name(
"h2d_mx");
cf.
copy(d_my, h_my.data(), K).
name(
"h2d_my");
}).name("h2d");
(N+1024-1) / 1024, 1024, 0,
assign_clusters, d_px, d_py, N, d_mx, d_my, d_sx, d_sy, K, d_c
1, K, 0, compute_new_means, d_mx, d_my, d_sx, d_sy, d_c
.
succeed(zero_c, zero_sx, zero_sy);
}).name("update_means");
tf::Task condition = taskflow.emplace([i=0, M] ()
mutable {
return i++ < M ? 0 : 1;
}).name("converged?");
cf.
copy(h_mx.data(), d_mx, K).
name(
"d2h_mx");
cf.
copy(h_my.data(), d_my, K).
name(
"d2h_my");
}).name("d2h");
cudaFree(d_px);
cudaFree(d_py);
cudaFree(d_mx);
cudaFree(d_my);
cudaFree(d_sx);
cudaFree(d_sy);
cudaFree(d_c);
}).name("free");
h2d.
succeed(allocate_px, allocate_py, allocate_mx, allocate_my);
kmeans.
succeed(allocate_sx, allocate_sy, allocate_c, h2d)
executor.
run(taskflow).wait();
}
class to create an executor for running a taskflow graph
Definition executor.hpp:50
tf::Future< void > run(Taskflow &taskflow)
runs a taskflow once
Definition executor.hpp:1573
class to create a task handle over a node in a taskflow graph
Definition task.hpp:187
void dump(std::ostream &ostream) const
dumps the task through an output stream
Definition task.hpp:573
Task & succeed(Ts &&... tasks)
adds precedence links from other tasks to this
Definition task.hpp:428
Task & precede(Ts &&... tasks)
adds precedence links from this to other tasks
Definition task.hpp:420
class to create a taskflow object
Definition core/taskflow.hpp:73
class to create a cudaFlow task dependency graph
Definition cudaflow.hpp:56
cudaTask zero(T *dst, size_t count)
creates a memset task that sets a typed memory block to zero
Definition cudaflow.hpp:1303
cudaTask kernel(dim3 g, dim3 b, size_t s, F f, ArgsT &&... args)
creates a kernel task
Definition cudaflow.hpp:1272
cudaTask copy(T *tgt, const T *src, size_t num)
creates a memcopy task that copies typed data
Definition cudaflow.hpp:1348
class to create a task handle over an internal node of a cudaFlow graph
Definition cuda_task.hpp:65
cudaTask & succeed(Ts &&... tasks)
adds precedence links from other tasks to this
Definition cuda_task.hpp:189
cudaTask & name(const std::string &name)
assigns a name to the task
Definition cuda_task.hpp:200
cudaTask & precede(Ts &&... tasks)
adds precedence links from this to other tasks
Definition cuda_task.hpp:182
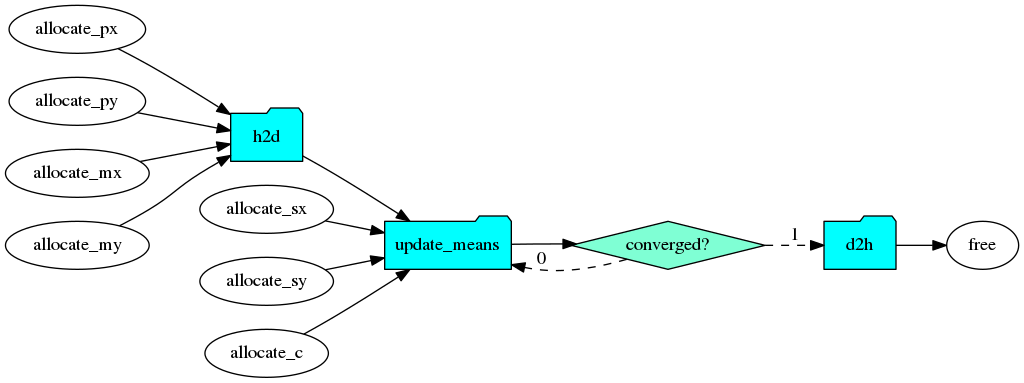
The first dump before executing the taskflow produces the following diagram. The condition tasks introduces a cycle between itself and update_means. Each time it goes back to update_means, the cudaFlow is reconstructed with captured parameters in the closure and offloaded to the GPU.
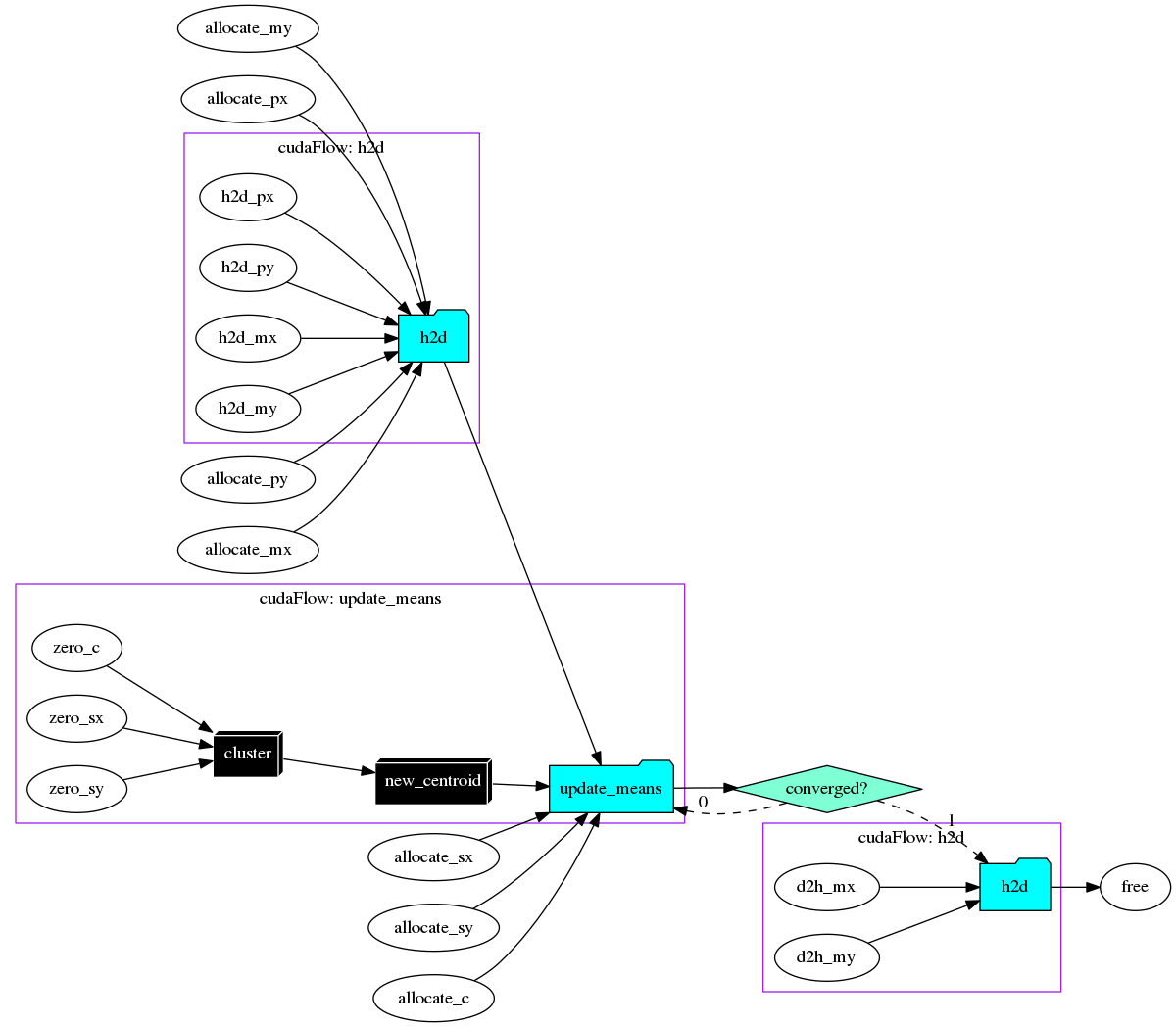
The second dump after executing the taskflow produces the following diagram, with all cudaFlows expanded:
The main cudaFlow task, update_means, must not run before all required data has settled down. It precedes a condition task that circles back to itself until we reach M iterations. When iteration completes, the condition task directs the execution path to the cudaFlow, h2d, to copy the results of clusters to h_mx and h_my and then deallocate all GPU memory.
Repeat the Execution of the k-means cudaFlow
We observe the GPU task graph parameters remain unchanged across all k-means iterations. In this case, we can leverage tf::cudaFlow::offload_until or tf::cudaFlow::offload_n to run it repeatedly without conditional tasking.
(N+1024-1) / 1024, 1024, 0,
assign_clusters, d_px, d_py, N, d_mx, d_my, d_sx, d_sy, K, d_c
).name("cluster");
1, K, 0,
compute_new_means, d_mx, d_my, d_sx, d_sy, d_c
).name("new_centroid");
.succeed(zero_c, zero_sx, zero_sy);
}).name("update_means");
h2d.
succeed(allocate_px, allocate_py, allocate_mx, allocate_my);
kmeans.
succeed(allocate_sx, allocate_sy, allocate_c, h2d)
void offload_n(size_t N)
offloads the cudaFlow and executes it by the given times
Definition cudaflow.hpp:1649
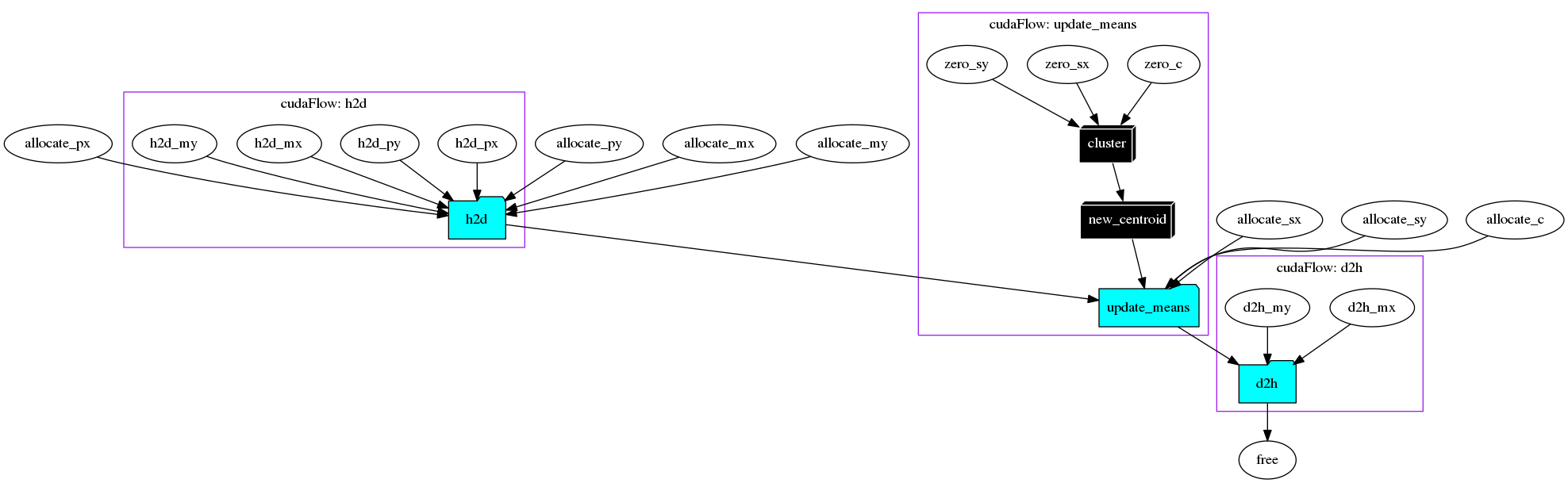
At the last line of the cudaFlow closure, we call cf.offload_n(M) to ask the executor to repeatedly run the cudaFlow by M times. Compared with the version using conditional tasking, the cudaFlow here is created only one time and thus the overhead is reduced.
We can see from the above taskflow the condition task is removed.
Benchmarking
We run three versions of k-means, sequential CPU, parallel CPUs, and one GPU, on a machine of 12 Intel i7-8700 CPUs at 3.20 GHz and a Nvidia RTX 2080 GPU using various numbers of 2D point counts and iterations.
| N | K | M | CPU Sequential | CPU Parallel | GPU (conditional taksing) | GPU (using offload_n) |
| 10 | 5 | 10 | 0.14 ms | 77 ms | 1 ms | 1 ms |
| 100 | 10 | 100 | 0.56 ms | 86 ms | 7 ms | 1 ms |
| 1000 | 10 | 1000 | 10 ms | 98 ms | 55 ms | 13 ms |
| 10000 | 10 | 10000 | 1006 ms | 713 ms | 458 ms | 183 ms |
| 100000 | 10 | 100000 | 102483 ms | 49966 ms | 7952 ms | 4725 ms |
When the number of points is larger than 10K, both parallel CPU and GPU implementations start to pick up the speed over than the sequential version. We can see that using the built-in predicate, tf::cudaFlow::offload_n, can avoid repetitively creating the graph over and over, resulting in two times faster than conditional tasking.