|
Taskflow
3.2.0-Master-Branch
|
|
Taskflow
3.2.0-Master-Branch
|
We study a fundamental clustering problem in unsupervised learning, k-means clustering. We will begin by discussing the problem formulation and then learn how to write a parallel k-means algorithm.
k-means clustering uses centroids, k different randomly-initiated points in the data, and assigns every data point to the nearest centroid. After every point has been assigned, the centroid is moved to the average of all of the points assigned to it. We describe the k-means algorithm in the following steps:
The algorithm is illustrated as follows:
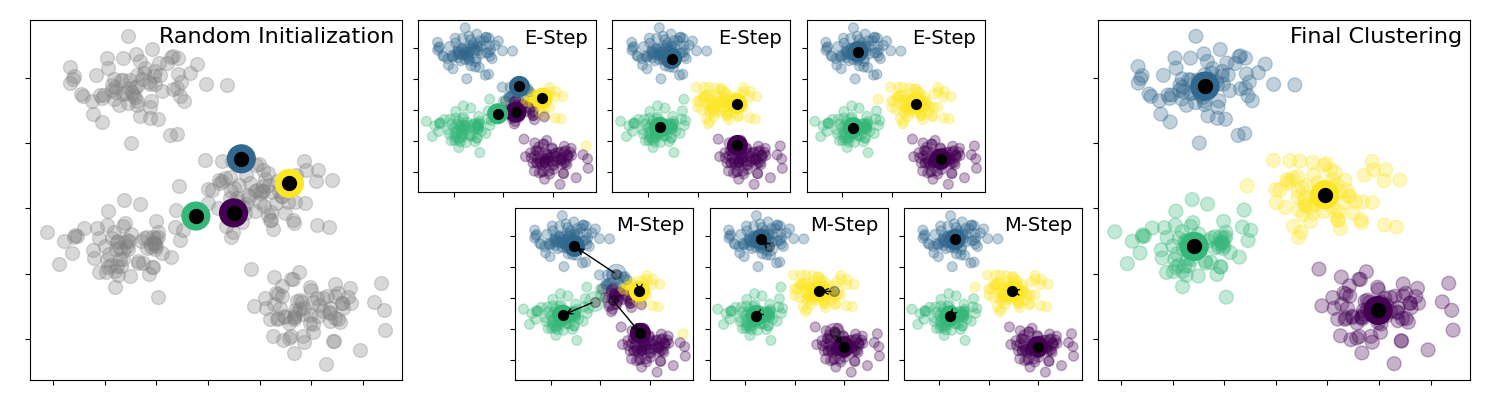
A sequential implementation of k-means is described as follows:
The second step of k-means algorithm, assigning every point to the nearest centroid, is highly parallelizable across individual points. We can create a parallel-for task to run parallel iterations.
The third step of moving every centroid to the average of points is also parallelizable across individual centroids. However, since k is typically not large, one task of doing this update is sufficient.
To describe M iterations, we create a condition task that loops the second step of the algorithm by M times. The return value of zero goes to the first successor which we will connect to the task of the second step later; otherwise, k-means completes.
The entire code of CPU-parallel k-means is shown below. Here we use an additional storage, best_ks, to record the nearest centroid of a point at an iteration.
The taskflow consists of two parts, a clean_up task and a parallel-for graph. The former cleans up the storage sx, sy, and c that are used to average points for new centroids, and the later parallelizes the searching for nearest centroids across individual points using 12 tasks (may vary depending on the machine). If the iteration count is smaller than M, the condition task returns 0 to let the execution path go back to clean_up. Otherwise, it returns 1 to stop (i.e., no successor tasks at index 1). The taskflow graph is illustrated below:
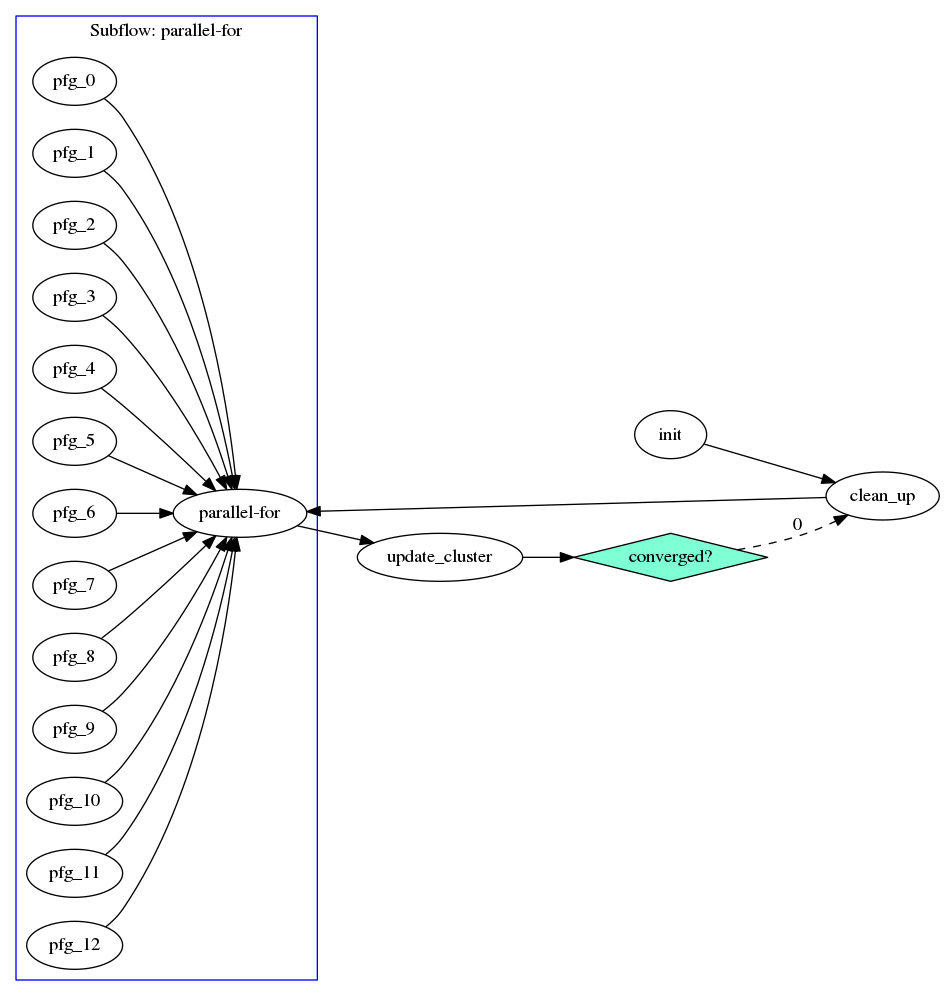
The scheduler starts with init, moves on to clean_up, and then enters the parallel-for task paralle-for that spawns a subflow of 12 workers to perform parallel iterations. When parallel-for completes, it updates the cluster centroids and checks if they have converged through a condition task. If not, the condition task informs the scheduler to go back to clean_up and then parallel-for; otherwise, it returns a nominal index to stop the scheduler.
Based on the discussion above, we compare the runtime of computing various k-means problem sizes between a sequential CPU and parallel CPUs on a machine of 12 Intel i7-8700 CPUs at 3.2 GHz.
| N | K | M | CPU Sequential | CPU Parallel |
|---|---|---|---|---|
| 10 | 5 | 10 | 0.14 ms | 77 ms |
| 100 | 10 | 100 | 0.56 ms | 86 ms |
| 1000 | 10 | 1000 | 10 ms | 98 ms |
| 10000 | 10 | 10000 | 1006 ms | 713 ms |
| 100000 | 10 | 100000 | 102483 ms | 49966 ms |
When the number of points is larger than 10K, the parallel CPU implementation starts to outperform the sequential CPU implementation.