在“运行syslog-ng”中我们简单介绍了一个基本配置文件的大概结构,保证syslog-ng能正常运行起来。这边将详细介绍下syslog-ng的日志配置及如何进行高效的配置,先介绍下syslog的一些基本知识:
日志级别及日志设备
syslog-ng和syslog一样,日志级别都有以下8种:
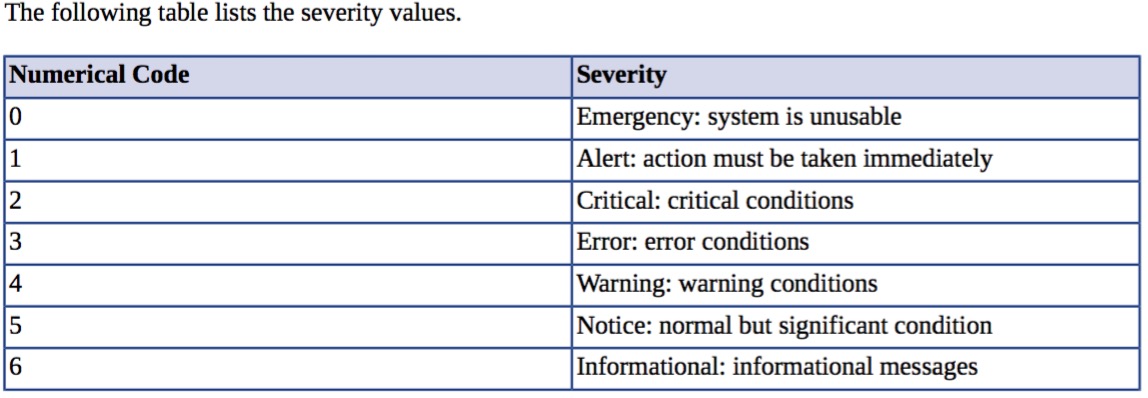
级别越低代表越重要的日志。
设备号有以下几种:
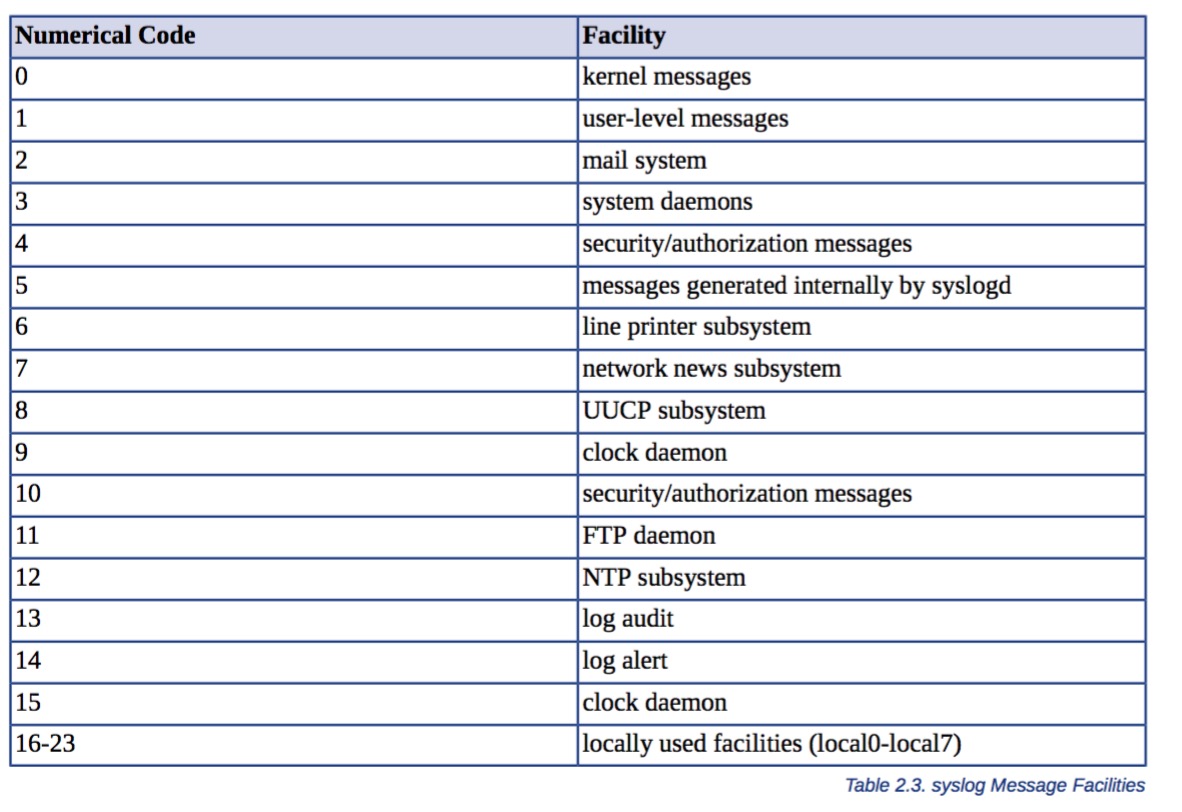
由设备号和日志级别我们可以计算出log的级别(facility_num * 8 + level_num)
使用syslog函数打印日志到syslog
了解了日志级别及日志设备后,我们就可以使用syslog函数来往设备(/dev/log)发送日志了(syslog-ng的system()设备其实就是获取送往/dev/log设备的日志,传统的syslog也会监控该设备)。函数用法可以使用man 3 syslog查看:
NAME
closelog, openlog, syslog, vsyslog - send messages to the system logger
SYNOPSIS
#include <syslog.h>
void openlog(const char *ident, int option, int facility);
void syslog(int priority, const char *format, ...);
void closelog(void);
使用例子如下:
openlog("redis_server", LOG_PID, 1); //设置设备号为1,ident(标识为redis_server),option为LOG_PID
syslog(LOG_DEBUG, "%s", “redis_server is started!”); //打印debug日志信息
loselog(); //使用完后关闭
了解完上面知识后,我们来看看如何对syslog-ng进行日志配置:
配置syslog-ng
基本语法
syslog-ng的配置文件为syslog-ng.conf,syslog-ng 运行时会解析该配置文件,然后对日志来源进行监听(看描述符是否可读),再对收集来的日志做一些指定的处理(如过滤,替换,格式化等)后,将日志写往各个destination:
log{
source(s_xxx);
filter(f_xxx);
destination(d_xxx)
};
其中source支持的设备主要有:file,network, tcp, udp, pipe, unix-dgram等
具体参见说明文档:Chapter 6. Collecting log messages — sources and source drivers
destination支持的有:file, network, syslog, redis, sql, hdfs, mongodb
具体参见说明文档:Chapter 7. Sending and storing log messages — destinations and destination drivers
(随着大数据和分布式时代的到来,syslog-ng也增加了对redis,hdfs等的支持,更新很快的,这也是开源的优势)
syslog-ng支持将收集的日志进行不同的处理,然后写入不同的目的地,这时候语法如下:
log{
source(s1);
source(s2);
{filter(f1); destination(d1);}
{filter(f2); destination(d2);}
};
格式化输出
格式化输出就是对捕获的日志进行排版,以一种方便阅读和使用的格式存储日志(如方便使用awk等进行日志诊断)。在日志格式化时,就不能不提syslog协议,其格式如下:
HEADER SYSLOGPRO_VERSION ISOTIMESTAMP HOSTNAME APPLICATION PROC_ID MESSAGEID STRUCTURED-DATA BOM(\xEF\BB\xBF) MSG
其中HEADER为信息头,通常包含信息长度(HEADER以后内容的长度)及日志优先级PRI(logFacility * 8 + logLevel), 具体说明请参考RFC5424The Syslog Protocol
举例:
<34>1 2003-10-11T22:14:15.003Z mymachine.example.com su - ID47 - BOM'su root' failed for lonvick on /dev/pts/8
对应的格式如下(这边没有proc_id,也没有structured data,两者都用’-‘替代了, BOM指出使用的是UTF-8编码):
<PRI>SYSLOGPRO_VERSION ISOTIMESTAMP HOSTNAME APPLICATION PROC_ID MESSAGEID STRUCTURED-DATA BOM MSG
在syslog-ng中,支持自定义日志格式,这时候我们可以使用template语法:
template global_format{
template("<${PRI}> ${ISODATE} ${HOST} ${PROGRAM} ${PID} ${MESSAGE}\n");
};
options { proto-template(global_format); }; #用于protocol-like destination, like syslog() and network()
options { file-template(global_format); }; #用于file-like destination
其中也可以使用${MSGHDR}来替代$PROGRAM[${PID}]的使用;新的syslog-ng版本也支持单独在template destination中指定template,则该template只会在该destination中生效(需要较新的syslog-ng版本才支持,比如3.4.2版本就不支持这种语法)。如:
destination d_file {
file ("/var/log/messages"
template("${ISODATE} ${HOST} ${MESSAGE}\n") ); #或template(template_name)
};
下面我们在syslog-ng.conf中实际操作以下,增加上面的template语法,然后启动syslog-ng,输出的日志变为:
<45> 2017-09-16T09:16:35+08:00 localhost syslog-ng 86650 syslog-ng starting up; version='3.4.2'
变量
syslog-ng中的marco变量十分丰富(如HOST, LEVEL_NUM等等)。此外,其还支持变量展开,作用类似shell脚本的$var功能: var=hello; echo $var ,下面来看看如何自定义和使用变量.
定义语法
使用@define语句定义一个变量(或者叫宏),如下:
@define local_loglevel 5
@define local_file “/va/log/messages”
使用语法
使用``符号进行变量展开,如:
filter f_level{“${LEVEL_NUM}” <= “`local_loglevel`“;}
文件包含
可以使用@include ‘filename’,将某个配置文件包含进syslog-ng.conf,这种语法在需要对配置文件拆分的场合很有用,如有个配置文件中的参数会变化(被外部修改),这时可以单独把这些参数放到另外的文件中,方便修改,也减少了破坏syslog-ng.conf文件的可能
filter
日志处理中最常用的filter当属级别过滤。此外,filter还具有很强大的关键字过滤功能,支持多个filter同时使用,具体语法参考Chapter 8. Routing messages: log paths and filters。
TLS传输
详见Chapter 10. TLS-encrypted message transfer
关于证书生成和配置的操作可参考证书相关概念及使用openssl生成自认证证书
其它
rewrite r_rewrite_set{set("myhost", value("HOST")};
condition(program("myapplication")));};
log {
source(s1);
rewrite(r_rewrite_set);
destination(d1);
};
- flow control
tcp: max-connections(300)
指定发送往网络目的地的日志缓冲区大小: log-fifo-size(40000)
在destination中启用flow control: flags(flow-control)
结语
syslog-ng支持的配置语法众多,具体可根据使用时查阅手册进行配置,本文讲解的是一些比较常用的操作,如有错误,欢迎指出。
后续会讲解下syslog-ng的源码,作为一个优秀的日志服务器和客户端,深入理解下应该还是能有不少收获的
